一枚硬幣連續擲出五次正面,同一條路線的列車在同一天發生了兩宗意外,或是隨機播放清單連續給你三首由相同歌手演唱的歌曲。這似乎並不是巧合,但真正的隨機也許未如我們想像中的那樣。
統計上獨立的事件:硬幣並沒有記性!
讓我們先從硬幣說起。擲一枚公平的硬幣(fair coin)時,很多人會預期正面和反面朝上的結果會交替出現,連續擲出正面大概會使我們目瞪口呆。在沒有細想之下,你可能也會估計正面和反面出現的次數會各佔一半,所以如果正面出現的比例多於一半時,反面應該就將會出現得更頻密來補償之前不均的結果 — 當然,這個想法是錯誤的,因為硬幣並不會記得先前的結果!如果你有一枚公平的硬幣,它連續擲出了99次正面朝上的結果,你不能說下次會有較大機會擲出反面,因為它畢竟是一枚公平的硬幣 [1]。由於每次拋擲對下次結果都沒有影響,我們稱這些為統計上獨立的事件。
如果我們擲兩次硬幣,每次正面或反面朝上的機會均等,以下是四個可能的結果:正正、正反、反正和反反。每個結果發生的機會都相同(1/4),但以任何次序出現一正一反的機率為2/4而不是1/4。擲三次的話會有八種可能:正正正、正正反、正反正、正反反、反正正、反反正、反正反和反反反,每種可能的機率均為1/8。一連擲十次的話,正反正反正反正反正反、正正反正反反反反正反和反反反反反反反反反反三者的機率都一樣,均為1/210或1/1024,可是會令你留下深刻印象的肯定是最後一個組合而不是其他 [2]。我們太著迷於從隨機產生的結果中找規律,並會就此輕率地下結論 [3]。
現實上的洗牌演算法:Fisher–Yates洗牌法與天真法
讓我們先介紹Fisher–Yates洗牌法 [2],它根據另一組隨機數字把序列隨機地打亂。假設現在有一組由數字1至10組成的序列。首先從1至10選一個隨機號碼叫 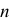 ,然後移除上述序列中第 個數字放到一組新序列裡。之後對序列中餘下的數字重覆以上步驟,從1至9、1至8中選 ,如此類推,直至序列中的所有數字都被移除(見圖一)。
,然後移除上述序列中第 個數字放到一組新序列裡。之後對序列中餘下的數字重覆以上步驟,從1至9、1至8中選 ,如此類推,直至序列中的所有數字都被移除(見圖一)。
|
原來序列 | 新序列 |
|---|---|---|
| 3 | 1 2 |
3 |
| 8 | 1 2 4 5 6 7 8 |
3 9 |
| 5 | 1 2 4 5 |
3 9 6 |
| 2 | 1 |
3 9 6 2 |
| 3 | 1 4 |
3 9 6 2 5 |
| 5 | 1 4 7 8 |
3 9 6 2 5 10 |
| 2 | 1 4 7 8 | 3 9 6 2 5 10 4 |
| 1 | 3 9 6 2 5 10 4 1 | |
| 2 | 7 |
3 9 6 2 5 10 4 1 8 |
| 1 | 3 9 6 2 5 10 4 1 8 7 |
圖一 Fisher–Yates洗牌法的一例
如果 的選擇是隨機的,那新序列也會是完全隨機的。讓我們來看看為甚麼這個關係會成立。我們可以以一副卡牌作比喻來理解這個演算法:每次隨機移除一張卡牌,並把移除的卡牌疊起來組成一副新的卡組。
把這個演算法與其他洗牌方法作比較可以突顯為甚麼Fisher–Yates法是真正隨機。有一個「天真(naïve)」的方法是每次在卡組中取出一張卡牌,然後與另一張隨機選擇的卡牌交換位置,再對卡組中的每張卡重覆以上步驟 [4]。換言之,如果我們用天真法洗一副有三張卡的卡組(卡牌上標記了#1、#2和#3),第一步我們會把卡組中的第一張卡與第一(不變)、第二或第三張卡的其中一張交換位置。然後到第二張卡,我們又使它與三張卡的其中一張對換位置;重覆以上過程直至卡組中的每一張卡都洗過一遍。
每一步我們都隨機從三張卡裡面選擇一張,因此三回合一共可以帶來3 x 3 x 3 = 33 = 27 個排列(permutations)結果。思路清晰的你大概已經意識到我們只有3 x 2 x 1 = 6種方式來排列三張卡牌:123, 132, 213, 231, 312和321。如果你把從天真法每一步產生的可能排列逐一列出,你會發現132, 213和231出現了五次,而123, 312和321只出現四次,結果顯然是偏倚的。憑直覺也能得知因為27並不能被6整除(基本上 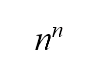 或 > 2都不能被 ! 整除),所以某些排列一定會比其他出現得更多(如果每個排列出現的機會均等,排列結果的數目應是6的倍數)。由於機會不均等,因此天真法並不隨機。
或 > 2都不能被 ! 整除),所以某些排列一定會比其他出現得更多(如果每個排列出現的機會均等,排列結果的數目應是6的倍數)。由於機會不均等,因此天真法並不隨機。
這與我們平時洗撲克牌的方式相似:簡單來說就是將卡組中的一疊卡牌與另一疊互換位置;可是這些方法都不會產生隨機的結果,因為洗過的卡牌都繼續在系統裡流轉。
跟Fisher–Yates法對比一下,由於每個回合都有一張卡被移除(並調到新的卡組中),所以被考慮的卡牌會越來越少,而在我們一副三張卡的例子裡,三回合只會帶來3 x 2 x 1 = 6個排列結果。計算這種排列結果數目的方法與計算三張卡牌有多少個排列可能性的方法一樣:兩者都用到階乘函數 ! = x ( – 1) … x 3 x 2 x 1;在我們的例子中是3! = 3 x 2 x 1,亦等同3P3。兩者背後的計算思路基本上相同,相同之處在於列出所有可能排列的方式。因此, 本身的隨機性在洗牌中被得以保留;這也是為甚麼只要能確保 是隨機選出的,就能保證Fisher–Yates法能提供一個完全隨機的序列。
創造不太隨機但感覺隨機的播放清單
現在回到我們在圖一的隨機序列:3-9-6-2-5-10-4-1-8-7。它是我們共有十首歌的隨機播放清單:曲目一、四、七、十是Adele(藝人甲)的歌,曲目二、五、八是BTS防彈少年團(藝人乙)的歌,而曲目三、六、九是Celine Dion(藝人丙)的歌。播放清單看來是這樣的:
Celine Dion ➜ Celine Dion ➜ Celine Dion ➜ BTS防彈少年團 ➜ BTS防彈少年團 ➜ Adele ➜ Adele ➜ Adele ➜ BTS防彈少年團 ➜ Adele
這樣的播放清單看起來一點兒也不隨機!這是因為我們不經意地聚焦在連續三首Celine Dion和Adele的歌這個不尋常的規律裡。假如你是2012至2014年的Spotify用家,你也許已經急不及待去投訴 [5] 這個不給你聽K-pop的該死隨機播放清單(假設你在2014年前已經在聽K-pop)。那年Spotify實在收到太多投訴,使他們放棄原來使用的Fisher–Yates演算法而引入新的演算法(對!他們原本是用Fisher–Yates法來產生隨機播放清單 [6])。現在選擇隨機播放時,演算法會確保由同一歌手演唱或屬於同一種類的歌曲大致平均地分佈在播放清單中 [7]。
正是Spotify工程師把播放清單弄得不再隨機,來令你相信它變得更加隨機。
參考資料:
- Lieberman, D. A. (2012). Human Learning and Memory. Cambridge, UK: Cambridge University Press. doi:10.1017/CBO9781139046978
作者︰香港科技大學《科言》學生編輯胡適之
設計︰香港科技大學《科言》學生設計師林曉薏
翻譯︰香港科技大學《科言》總編輯劉劭行
2022年9月